Отличительные особенности БД комплекса «Викта»
Физическое строение файла базы данных
База данных «Викта» представляет собой один физический файл, куда последовательно пишутся все записи базы данных. Каждая запись содержит в себе: время ее выполнения и набор реквизитов, соответствующий данной записи. Количество записываемых реквизитов, их типы и наименования никак не ограничиваются. При этом, при добавлении или изменении данных какой-либо записи базы, вместо правки уже существующей записи происходит добавление новой в конец файла. Т.е. все изменения данных в БД «Викта» записываются потоковым методом, - без правки уже имеющихся данных. При выполнении операции чтения актуальной считается последняя по времени запись.
Такой подход существенно снижает накладные расходы, связанные с изменением и удалением записей в базе (нет нужды искать конкретное место БД в котором необходимо произвести изменение). Кроме этого, он позволяет реализовать уникальную возможность, полностью отсутствующую в любых других имеющихся СУБД: получение полностью консистентного состояния базы на любой заданный момент времени в исторической перспективе. Например, если требуется получить по состоянию на прошлую неделю, или двумя днями ранее, то в комплексе «Викта» этот подход реализуется очень просто: чтение базы ведется до момента, указанного в запросе пользователя: все более поздние данные не принимаются во внимание.
Логическая структура данных
Логическая структура базы задается путем набора реквизитов и логических файлов. Реквизит – это описание элементарной единицы информации, содержащее в себе ее наименование, описание и тип (текстовый, числовой, дата и т.п.).
Логический файл – это некоторое подмножество записей физического файла БД, с семантической точки зрения объединенный по некоторому общему признаку. Если сравнивать с реляционной СУБД, логический файл можно сравнить с таблицей, но это сходство весьма условно. На уровне СУБД, для каждого логического файла задается один или несколько реквизитов, которые будут составлять первичный ключ файла. Как и в реляционной СУБД, не допускается наличие двух записей с идентичными значениями первичного ключа в одном файле. Все остальные реквизиты логического файла в теории, могут быть какими угодно, - главное, чтобы они принадлежали общему списку реквизитов базы. На практике это приводит к тому, что в одном логическом файле содержатся все записи, содержащие некоторый минимальный общий набор характеристик и в дополнение к этому, - какой-то свойственный только им одним персональный набор. При таком подходе на базе одного логического файла становится очень просто реализовать объектный подход: все экземпляры заданного объекта и всех его потомков могут храниться в одном логическом файле, что устраняет необходимость создания дополнительных логических файлов для хранения дополнительных полей, специфических для объекта заданного типа. Примером может служить объект «Каталог товаров», минимальным набором реквизитов которого является Код, Наименование и Стоимость товара. Имея возможность заносить в один логический файл записи с совершенно разным набором характеристик, мы вполне можем в логический файл «Каталог товаров» заносить информацию о Продуктах питания, Молочной продукции, Канцелярских товарах и т.п. Каждое из этих понятий обладает своим собственным набором реквизитов, характеризующих данный объект. Мы можем подразделить наши товары на всевозможные типы и категории, и все они будут размещаться в одном логическом файле. Этот подход позволяет существенно сократить количество логических файлов (таблиц), при реализации задачи для заданной предметной области и, соответственно, существенно упростить восприятие всей схемы данных в целом. При этом наличие одного файла существенно упростит процедуру поиска по каталогу и по схожим характеристикам товаров: в виду отсутствия лишних связей, поиск не составит особых проблем, а для дальнейшей оптимизации скорости выборки нам ничто не помешает проиндексировать этот файл по интересующим нас реквизитам (в дополнение к индексу по ключу).
Доступ к данным
В БД «Викта» доступ реализуется через API, дающий прямой доступ к структурам данных файлов. В некоторых случаях это налагает дополнительную работу на разработчика задачи, поскольку требует постоянного повторения рутинных алгоритмов выборки данных (по этой причине разработчики системы осознают необходимость введения поддержки SQL и планируют это сделать в будущих версиях). С другой стороны, - прямой доступ к данным позволяет устранить промежуточный слой обработки данных (нет необходимости гонять массивы данных сначала на уровне внутреннего обработчика SQL запросов, а затем, - уже пользователем на уровне приложения). Вторым преимуществом является тот факт, что алгоритмический язык является более универсальным инструментом, чем язык SQL-запросов и в отдельных случаях позволяет реализовать некоторые алгоритмы выборки данных существенно более оптимальным способом, нежели это возможно сделать средствами SQL.
Организация многопользовательской работы
Организация многопользовательской работы: каждый пользователь базы работает с ее локальной копией, расположенной непосредственно на машине пользователя. Любое чтение данных осуществляется только из локальной копии базы, что устраняет лишнюю нагрузку на сеть и все связанные с этим издержки, как в случае наличия централизованного сервера.
В контексте многопользовательской работы также крайне важным является тот факт, что БД «Викта» разрабатывалась совместно с фреймворком «Викта», предназначенным для создания информационно-учетных систем. В контексте данной задачи конечным пользователем системы является потребитель конечного решения (например, бухгалтер), работающий со своим клиентским интерфейсом. Для этого клиентского интерфейса, БД «Викта» по сути является встроенной, - конечный пользователь ничего не знает о ее существовании и, естественно, не требуются никакие дополнительные затраты на отдельную установку и администрирование локальной БД.
Для реализации многопользовательской работы в БД «Викта» существует и отдельно выделенный сервер. На него возлагаются задачи получения информации об изменении данных от станций, контроля транзакционной целостности, выполнение всевозможных перерасчетов, требующих изменения данных в базе, и распространения информации об изменениях межу всеми станциями системы. Информация передается пакетами транзакций, чтобы не разрушать целостность данных. Передача осуществляется в широковещательном режиме (broadcast), - для распространения данных об изменении по рабочим станциям серверу не требуется устанавливать отдельное соединение с отдельно взятой рабочей станцией, что позволяет существенно сократить накладные расходы на распространение информации и упростить процесс добавления новой станции в сеть: при подключении, она должна просто «настроиться на волну» по которой сервер передает данные.
Фон
Фон, - это специальный процесс, работающий на сервере, на который возлагаются всевозможные задачи по контролю и обработке всей поступающей в систему информации: проверки, перерасчет всевозможных вычисляемых значений, агрегатов, остатки и т.п.
Наличие такого процесса на уровне сервера позволяет налету перерасчитывать все вычисляемые значения прикладной задачи, и записывать получившиеся данные в базу. Процедуры фонового процесса применяются к каждой новой поступившей записи (в этом контексте они похожи на триггеры в БД). При этом, поскольку перерасчет выполняется при поступлении каждой новой записи, задача вычисления средних, суммарных значений, остатков и т.п. сводится к простым арифметическим операциям, что устраняет необходимость реализации сложных алгоритмов вычисления, требующих оперирования большими массивами данных, лежащих в базе.
Наличие такого подхода позволило сохранять логически и семантически целостное состояние базы на любой момент времени: отсутствуют ночные процедуры перерасчета агрегатов, любой отчет работает с актуальными данными в режиме реального времени. Более того, такое актуальное состояние (включая все расчетные значения), можно получить на любой момент времени в исторической перспективе (вспомним про особенности физического строения общего файла данных базы).
Блокировки
Любой администратор БД, имеющий большой практический опыт работы с БД, знает, какое количество проблем создает факт наличия блокировок на сервере с точки зрения замедления работы системы в режиме многопользовательской работы. При этом все понимают, что для контроля целостности данных в современной реляционной базе наличие блокировок необходимо и поэтому усилия по решению этой проблемы направлены на устранение возможных причин возникновения блокировок: разделение тяжелых вычислительных задач и массовой работы пользователей по различным временным промежуткам, максимальное сокращение времени исполнения одной транзакции, оптимизация алгоритмов и запросов и т.д и т.п.
В БД «Викта» проблема блокировок отсутствует как класс по причине отсутствия самих блокировок. При этом база гарантирует целостность и консистентность данных на любой момент времени. Для того, чтобы понять, как это происходит и проявить суть различий, нужно несколько глубже углубиться в принципы работы этой БД.
Итак, предположим ситуацию: имеется в наличии сервер и две рабочих станции, в клиентских приложениях которых две операционистки в один и тот же момент времени редактируют один и тот же документ. Вспомним, что каждая рабочая станция обладает полностью актуальной локальной копией файла базы данных. Итак, на начальный момент времени, мы имеем следующее состояние базы:

На рисунке указано, что сервер и все три станции работают с некоторым состоянием базы на момент времени равный T1. На этот момент времени последней транзакцией в базе является транзакция с номером 7. Обе операционистки формируют данные для новой транзакции (у нее пока еще нет номера, но мы будем считать, что данные формируются для восьмой транзакции).
Допустим, операционистка станции 1 первой закончила редактирование документа и нажала кнопку сохранения. Данные ушли на сервер, выполнилась новая транзакция, соответствующая информация была распространена по рабочим станциям. После выполнения этой операции, мы придем к следующему состоянию:
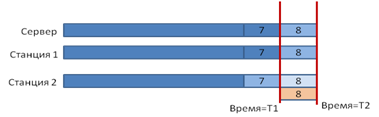
Здесь все станции получили обновленное состояние базы, но при этом операционистка второй станции продолжает работать с состоянием базы, которым оно было на момент времени T1, поскольку данные, которые она видит на своем экране, были прочитаны раньше момента совершения обновления, - то есть она продолжает работать с состоянием, актуальным на момент завершения седьмой транзакции и продолжает формировать данные для следующей. Если она в этот момент завершит свою работу и изменившиеся данные пойдут на сервер, он не сможет записать ее данные и сообщит на станцию об ошибке (вспомним, что они редактировали один и тот же документ). Если бы операционистка второй станции работала с другим документом, конфликта бы не возникло, и данные успешно были бы записаны в базу (в этом случае операция второй операционистки просто записалась бы под номером 9). В данном случае это не так, и операционистке будет предложено либо отменить свою операцию, либо просмотреть и откорректировать данные, измененные другой операционисткой (сделать изменения в базе на основании состояния, имеющегося в момент времени T2).
Таким образом, база отрабатывает ситуацию конфликта только на уровне отдельно взятой записи и, фактически, постфактум, что, на первый взгляд, налагает дополнительную нагрузку на разработчика при разработке системы (он должен корректно отработать эту ситуацию). Однако, практика эксплуатации подобной системы показала что: подобные конфликты возникают крайне редко, а отсутствие механизма блокировок устраняет вопросы, связанные с вынужденным ожиданием пользователей при чтении и обновлении данных имеющих отношение к изменяемой записи.
Более того, на практике, подобная система обладает гораздо большей защищенностью именно с точки зрения семантики данных по сравнению с современными системами, созданными на базе классической реляционной СУБД. Для того чтобы это пояснить, необходимо рассмотреть этот же пример, но реализованный в классической системе клиент-сервер.
Итак, мы имеем сервер БД и двух операционисток, на рабочих станциях которых работает клиентское приложение, взаимодействующее с сервером БД. Обе операционистки открыли на редактирование один и тот же документ. С точки зрения системы клиент-сервер это означает, что было выполнено два одинаковых запроса к базе, данные были переданы клиенту и отображены в клиентской форме редактирования. Начиная с этого момента база ничего не знает ни о каких изменениях, совершенных операционистками, а клиентское приложение ничего не знает о транзакционном состоянии базы.
Продолжаем развитие того же сценария: операционистка 1 закончила работу и нажала кнопку сохранения. Данные ушли на сервер. Сервер открыл транзакцию, записал данные и закрыл транзакцию, до этого момента все внешне происходит точно так же. Далее операционистка 2 заканчивает редактирование и отправляет данные на сервер. Сервер, поскольку он ничего не знает о том, что операционистка 2 проводила изменение документа, основываясь на уже потерявшем свою актуальность состоянии данных, спокойно открывает транзакцию, производит запись и закрывает ее. В данном случае с точки зрения базы конфликта не произошло, целостность нарушена не была, но с точки зрения семантики данных, такая ситуация не допустима, так как операционистка 2 фактически перекрыла работу операционистки 1.
Обычно, при грамотном проектировании систем на основе современных реляционных СУБД задачу подобного семантического контроля решают разработчики прикладной задачи: взятый на редактирование документ помечается как заблокированный и всем остальным он становится доступным только в режиме чтения. То есть, программисты должны заниматься разрешением конфликтов, которые в идеале должна решать база.
Отчеты
Здесь под отчетом подразумевается некоторое представление имеющийся в базе информации, для реализации которого требуется проводить выборку и преобразование значительных объемов данных из базы, но при этом отсутствует необходимость записи каких-либо параметров в базу или вычисления, производимые в отчете, носят локальный характер и не затрагивают работу остальных пользователей.
Любой такой отчет формируется на стороне пользователя. При этом, поскольку в арсенале пользователя имеются все необходимые агрегаты и на чтение система фактически работает в однопользовательском режиме, формирование отчета, как правило, не занимает слишком много времени (максимально длительная по времени задача за всю историю существования комплекса – 2 минуты). Кроме того, система предусматривает возможность формирования отчета в фоновом режиме (в этом случае отчет будет формироваться по данным, актуальным на момент старта вычислений) с одновременным предоставлением пользователю возможности дальнейшей работы с данными.
Такой подход обладает следующими преимуществами:
- отсутствует лишняя нагрузка на сервер, что снижает требования к его производительности.
- выполнение сложных отчетов никаким образом не затрагивает работу других пользователей комплекса.
Заключение
Таким образом, отличительными особенностями БД «Викта» являются:
- Возможность просмотра состояния базы на любой заданный момент времени в исторической перспективе включая полностью актуальное на любой момент времени состояние всех агрегированных данных.
- Возможность внесения в один логический файл (таблицу) записей, содержащих различные множества реквизитов и возможность создания индекса по этим реквизитам.
- Отсутствие блокировок на чтение и запись данных с одновременным полным семантическим контролем данных на уровне сервера БД.
- Отсутствие задержек, связанных с чтением и записью данных в связи с конкурентным доступом к данным.
- Отсутствие задержек, связанных с чтением данных из-за необходимости передачи данных по сети.
- Отсутствие необходимости в наличии мощного централизованного сервера, обрабатывающего информацию всех пользователей.
- Естественная отказоустойчивость: поскольку каждый пользователь обладает полной копией всех данных, отсутствуют проблемы, связанные с возможной потерей данных в связи с выходом из строя серверного оборудования (в случае потери сервера, сервером можно объявить любую из рабочих станций).